
Excelente texto de Grant Fritchey publicado em: 8 July 2014 na simple-talk.com
Verificando o código do programa no controle de origem é um ritual diário para a maioria dos desenvolvedores, mas versionamento de código de banco de dados é menos bem compreendido. Grant Fritchey argumenta que a obtenção de seus bancos de dados sob controle de origem não só é vital para a estabilidade do desenvolvimento e implantação, mas vai facilitar a sua vida quando algo der errado.
Desenvolvimento de software é uma disciplina difícil e exigente. Ele fica ainda mais difícil quando você traz equipes de desenvolvedores juntos em um único projeto. Uma das questões fundamentais se dá em torno do próprio código. Quem é responsável pelo quê pedaço dele? Que mudanças fizeram? Como você recebe essas mudanças de um membro da equipe para a próxima? Como você mantém um histórico de cada mudança, no caso de causar problemas mais tarde que você precisa para rastrear e corrigir? A resposta a todas estas perguntas, e muito mais, é o de gerir o seu código através de um sistema de controle de origem.
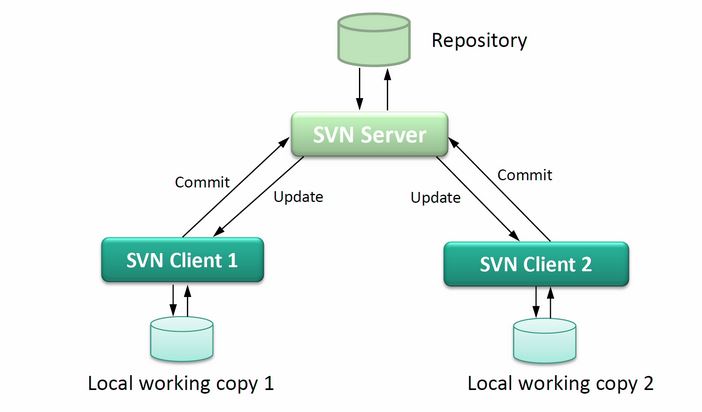
Sistemas de controle de origem, também chamados de sistemas de controle de versão (VCS) ou sistemas de controle de revisão, remontam ao nascimento da computação moderna. Um dos primeiros a desenvolver foi em 1975, quando havia, finalmente, espaço em disco suficiente para armazenar uma segunda cópia do programa, apenas no caso. Desde então, obter o código do aplicativo para controle de origem tem ido além de ser uma prática padrão da indústria para simplesmente uma parte da programação, como escrever uma função ou uma cláusula IF. Sim, existem algumas lojas ou desenvolvedores individuais que não usam o controle de origem para o seu código, mas essas são as exceções gritantes que confirmam a regra quase universal que o código vai para o controle de origem.
Mas os bancos de dados são diferentes.
A história dos bancos de dados diverge da história do código. Em algum momento, os desenvolvedores não foram responsáveis por bancos de dados. Em vez disso, eles se mudaram para as mãos dos administradores de sistemas e administradores de bancos de dados dedicados, que, francamente, olhou para o mundo um pouco diferente do que os desenvolvedores. Eles gastaram tempo se preocupando com backups, disponibilidade, integridade e performance.
Em muitos casos, o trabalho de desenvolvimento de banco de dados mudou-se para o reino do DBA. Enquanto muitos DBAs veio das fileiras dos desenvolvedores, eles gastaram mais tempo se preocupando com todas essas tarefas de administração do que as tarefas de desenvolvimento, e algumas das melhores práticas e métodos criados para a gestão de código só não foram aplicados em bancos de dados. Mas eles devem ser.
Backups
DBAs são muito bons em colocar em esquemas de backup local que irão proteger os dados de produção. No entanto, quando se trabalha com o código de um banco de dados e SQL que define as estruturas de dados e procedimentos armazenados não é nada além de código, um backup completo do banco é um dispositivo pesado por que manter cópias do esquema, para a recuperação de mudanças e rastreamento histórico . Por exemplo, para descobrir o que mudou entre as versões anteriores e atuais de um procedimento armazenado um DBA seria forçado a usar uma ferramenta de terceiros que poderia comparar diretamente para um backup, ou para executar uma restauração completa do banco de dados para um local secundário e, em seguida, extrair a definição do procedimento armazenado. Isso nem sempre é possível, é frequentemente impraticável e é, certamente, vai ser lento.
Conseguir um banco de dados no controle de origem fornece um mecanismo muito mais eficiente para fazer o backup do código SQL para o banco de dados. Recuperar uma versão anterior de um procedimento armazenado a partir implica simplesmente inspecionando o histórico de alterações dentro de sua VCS. A recuperação é quase instantânea.
Quando você percebe que seu SQL é um código, ele imediatamente faz sentido usar os mesmos mecanismos de backup que utiliza o código, que é um VCS.
Auditoria
Na maior parte dos sistemas de gerenciamento de banco de dados, é possível saber quando um objeto foi criado ou modificado pela última vez, e que o login realizada essa ação. No entanto, normalmente não há registro histórico de todas as alterações anteriores a esse objeto. Além disso, de acordo com o mecanismo de segurança no banco de dados, você pode simplesmente ver que um administrador de sistema ou banco de dados proprietário fez a alteração, sem nenhuma indicação sobre a identidade real da pessoa que trabalha dentro desse papel.
Se você tem seu banco de dados em um VCS, eo uso que VCS como uma parte fundamental do seu desenvolvimento e mecanismos de implementação, então ele irá fornecer exatamente esse tipo de rastreamento. Todas as mudanças são originários da VCS e não são feitas diretamente contra o sistema de produção fora do processo em torno de sua VCS. Você vai saber quem fez o que e quando a mudança foi feita.
Muitas organizações têm de cumprir os requisitos legais para a auditoria de alterações, tais como aquelas adotadas pelo Sarbanes-Oxley. A implementação de um VCS poderia ser a maneira mais rápida e fácil para fornecer o nível necessário de rastreamento histórico de todas as alterações de modo que para cada mudança no banco de dados que você sabe quem fez isso e quando.
Integração
Assim que entramos em um novo arquivo de código no VCS, ele atribui a ele uma versão. Cada vez que cometer uma mudança para esse arquivo, os incrementos de versão, e nós temos acesso à versão atual e todas as versões anteriores do arquivo. Quando colocamos um banco de dados para os VCS, isso significa que todos os objetos de banco de dados (tabela, visão procedimento armazenado e assim por diante) na VCS tem um número de versão. Podemos também criar etiquetas ou tags, que nos permitem atribuir significativo “número de compilação” para o conjunto de arquivos que compõem uma determinada versão de um banco de dados.
Além disso, ter o banco de dados no controle de origem diretamente ao lado do aplicativo irá integrar as alterações de banco de dados com as alterações de código de aplicação, de forma que você sempre saberá que a versão do banco de dados a ser implantado diretamente corresponde à versão do aplicativo que está sendo implantado. Esta integração direta ajuda a assegurar uma melhor coordenação entre as equipas e pode ajudar na solução de problemas.
Automatizando implantações
Se todas as alterações necessárias para um sistema de produção estão em um banco de dados de desenvolvimento em algum lugar, em vez de dentro de um VCS, as implantações são necessariamente vai ser um caso de manual. Você vai precisar de um processo que vai gerar mudanças a partir do seu banco de dados de desenvolvimento, a fim de tornar o banco de dados de produção espelhar o projeto mais recente. Existem produtos de terceiros que podem ajudar, mas como é que se diferenciar entre os objetos que se destinam a sair com uma versão e objetos que se destinam a sair com uma versão diferente do seu código? De dentro de um banco de desenvolvimento é freqüentemente impossível, já que não há métodos claros e fáceis para diferenciar objeto muda dentro desse banco de dados.
Uma vez que você começar a gerar seus scripts de implantação de controle de origem, uma série de oportunidades se abrem. Você vai ser capaz de diferenciar os objetos de banco de dados em versões conhecidas, que lhe permitirá controlar o que está sendo implantado. Uma vez que você pode controlar o que está sendo implantado, você pode trazer de automação para suportar sobre o processo de implantação. Você vai ser capaz de tirar partido da integração contínua e de outros mecanismos de implantação e testes automatizados que o código do aplicativo já usa. Implantações automatizadas também significa mais testes e validação dessas implementações que podem ajudar a garantir a implantação final a produção é bem sucedida.
Conclusão
Desde o SQL que define um banco de dados é o código, ele só faz sentido para aproveitar os mecanismos existentes e estabelecidas há muito tempo para gerenciar esse código. Você vai ter uma maneira melhor de backup que código, e, mais importante, recuperar versões anteriores de que o código. O controle de origem para o banco de dados fornece uma trilha de auditoria para ajudar na solução de problemas e conformidade legal. Você terá uma melhor integração com o código do aplicativo por meio do gerenciamento de código compartilhado. Finalmente, você vai ser capaz de automatizar as implantações. Todas estas razões torna a colocar as bases de dados no controle de origem uma jogada inteligente para ajudar a melhorar a gestão dos sistemas dentro de sua organização.
Considerações:
Eu já participei da implementação e do processo de construção de banco de dados dentro de sistema VCS que foi atribuído dentro de uma indústria do ramo de nobreaks.
A princípio achei burocrático, fui birrento em ter que atualizar VCS toda vez que fosse atualizar códigos que os desenvolvedores nos enviava para análise e implementação. Você só percebe o quanto é importante este controle de versão quando precisa dele. No caso, passou-se uma semana e os gestores queria saber qual código havia subido para produção, em qual dia e qual estado o banco de dados se encontrava naquele momento. Toda essa informação demandaria tempo de depuração de código e banco de dados, e como todos nós sabemos, tempo é o que um DBA menos tem (principalmente sobre pressão).
Conclusão: Descobri em poucos minutos através do VCS em qual versão o código subiu para o banco de produção, a data, quem criou o código e pudemos (claro com boa política de backup) restaurar parte da informação que o código havia modificado, e todos ficaram felizes para “sempre”. (Um sempre que não dura muito rs).
Próximo post ensinarei conceitos, boas práticas e mais dicas de utilização assim como os VCS mais usados em mercado atualmente.


Deixe um comentário