
O índice columnstore foi introduzido pela primeira vez no SQL Server 2008R2 com o PowerPivot ( https://technet.microsoft.com/en-us/library/ff628113(v=sql.100).aspx ). Esta tecnologia foi adotada no motor de SQL Server 2012 com algumas alterações e foi surgiu como um índice columnstore não agrupado (NCCI). O NCCI foi um índice de somente leitura que direcionados para acelerar a análise na tabela / partições que são somente leitura.
O que é columnstore?
O columnstore representa um novo formato de armazenamento de dados relacionais. Ele armazena dados como colunas em vez de linhas, como mostrado na figura abaixo representa uma tabela relacional com 5 colunas. Note, porém os dados são armazenados como colunas, você ainda pode consultar a tabela para buscar a linha com todas as suas colunas, mas é mais caro para rowstore onde todas as colunas são armazenados juntos.
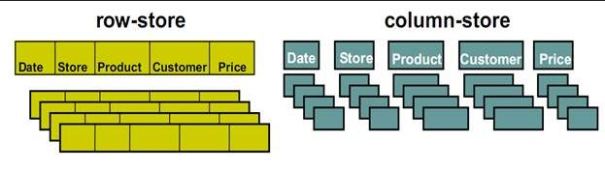
Quais os benefícios oferece o columnstore?
- Armazenamento reduzido: Os dados são armazenados em colunas individuais, onde são muito bem comprimidos pois, todos os valores são retirados do mesmo domínio (tipo de dados) e em muitos dos casos os valores são semelhantes ou se repetem. O ganho é de até 10x na compressão onde pode ser até maior o ganho, depende da distribuição dos dados. O importante é que isso permite que você reduza o espaço de armazenamento do banco de dados significativamente.
- I/O reduzido devido à compressão: Grandes consultas que processar um grande numero de linha comumente levam um tempo considerável para lhe retornar um resultado. Isso pelo custo da grande quantidade de I/O que a mesma pode gerar em disco. Uma maneira rápida de para acelerar estas consultas é reduzindo o I/O. A compressão de dados acelera consultas analíticas por causa da redução proporcional IO, bem como o aumento da probabilidade de que os dados solicitados podem ser encontrados na memória.
- Somente colunas referenciadas precisam ser buscadas: Na grande maioria das analises/consultas são requisitados um pequeno conjunto de colunas. Com columnstore o SQL Server precisa buscar apenas as colunas referenciadas ao contrário do rowstore que precisa obter a linha completa independentemente do número de colunas referenciadas na consulta.
SQL Server 2016 fornece duas funções de índice columnstore; Cluster (CCI) e sem cluster(NCCI).
Os dois índices são armazenados em colunas, mas NCCI é criado em uma tabela rowstore como mostrado na figura ao lado direito a baixo, enquanto uma tabela com CCI não tem tabela rowstore. Todas as duas tabelas podem ter um ou mais arvores btree de índices agrupados.
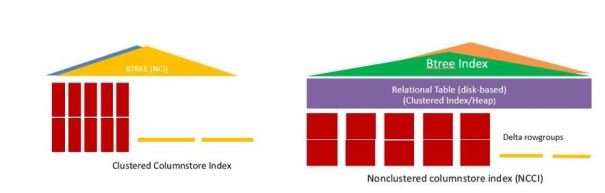
Tirando isso, as estruturas físicas sobre como os dados são armazenados em delta e rowgroups comprimido são idênticos e ambos os tipos de índices têm mesmas otimizações de desempenho, incluindo os operadores BATCHMODE.
Vamos falar mais de columstore no SQL Server 2016 no próximo post.


Deixe um comentário