
Sabemos que um dos grandes responsáveis pelo grande volume de dados (BIG DATA) do atual momento do mundo é gerado por sistemas de bancos de dados que armazenam a informação de vários aplicativos e durante um determinado tempo.
Quando grandes analisadores de dados entraram em cena, tais como Hadoop, Casandra, Pig, MapReduce… foi necessário a interação entre esses sistemas e os grandes armazenadores de dados. E é ai que entra o Sqoop.
O que é o Sqoop?
Basicamente é uma ferramenta do Hadoop projetada para estabelecer conexão através de JDBC à bases de dados como MySQL, Oracle, SQL Server etc..
Dessa forma você não precisa ficar importando arquivos para o HDFS, ao em vez disso você importa os dados diretamente do RDBMS (sistema gerenciador de banco de dados relacional) através do Sqoop.
O Sqoop é responsável pela conexão a uma base de dados onde se consegue fazer a importação de uma/várias ou todas as tabelas de uma determinada base de dados diretamente para o HDFS e mais, é possível fazer o contrário também, importar do HDFS os arquivos processados pelo Hadoop para o RDBMS.

Sem muitas delongas, vamos a instalação, porque o negocio aqui é mão na massa:
*Como Sqoop é um sub projeto do Hadoop, ele só pode funcionar no sistema operacional Linux. Siga os passos indicados abaixo para instalar o Sqoop no seu sistema.
1 – VERIFICAR INSTALAÇÃO DO JAVA
$ Java -version
Se o java já estiver instalado aparecerá parecido com.
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
————————————————————————–
Caso precise instalar pode-se seguir os seguintes passos, desde que já tenha baixado o java para a maquina.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Para tornar o Java disponível para todos os usuários, você deve movê-lo para o local “/ usr / local /”. Abra a raiz e digite os seguintes comandos.
$ su password: # mv jdk1.7.0_71 /usr/local/java # exitStep IV:
Configurando as variáveis de ambiente. Adicionar os comandos no ~/.bashrc.
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin
Aplicando as alterações para todo sistema atualmente em execução.
$ source ~/.bashrc
Configurando as alternativas Java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
Agora verifique a instalação usando o comando java -version do terminal como explicado acima.
2 – INSTALAÇÃO HADOOP
Baixe e instale o Handoop. No caso a baixo estamos usando a versão 2.4.1.
# cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
*Instalaremos em modo Pseudo distribuído. O Hadoop é configurado no modo pseudo-distribuído com cada serviço rodando em uma instância própria da JVM, mas todas na mesma máquina.
Configurando o Hadoop.
Você pode definir variáveis de ambiente Hadoop adicionando os seguintes comandos ao arquivo ~ / .bashrc.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Aplique todas as alterações no sistema em execução atual.
$ source ~/.bashrc
Você pode encontrar todos os arquivos de configuração do Hadoop no local
“$ HADOOP_HOME / etc / hadoop”. É necessário fazer alterações adequadas nesses arquivos de configuração de acordo com a infra-estrutura do Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
A fim de desenvolver programas de Hadoop usando java, você tem que repor as variáveis de ambiente java em hadoop-env.sh arquivo, substituindo o valor JAVA_HOME com a localização do Java em seu sistema.
export JAVA_HOME=/usr/local/java
Abaixo está a lista de arquivos que você precisa editar para configurar o Hadoop.
Core-site.xml
O arquivo core-site.xml contém informações como o número da porta usada para a instância do Hadoop, a memória alocada para o sistema de arquivos, o limite de memória para armazenar os dados e o tamanho dos buffers de Leitura / Gravação.
Abra o core-site.xml e adicione as seguintes propriedades entre as tags <configuration> e </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000 </value> </property> </configuration>
Hdfs-site.xml
O arquivo hdfs-site.xml contém informações como o valor dos dados de replicação, o caminho namenode eo caminho do datanode de seus sistemas de arquivos locais. Significa o lugar onde você quer armazenar a infra-estrutura do Hadoop.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value> </property> </configuration>
Nota: No arquivo acima, todos os valores de propriedade são definidos pelo usuário e você pode fazer alterações de acordo com a sua infra-estrutura Hadoop.
Yarn-site.xml
Este arquivo é usado para configurar o Yarn no Hadoop. Abra o arquivo yarn-site.xml e adicione as seguintes propriedades entre as tags , neste arquivo.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Mapred-site.xml
Este arquivo é usado para especificar qual estrutura MapReduce estamos usando. Por padrão, o Hadoop contém um modelo de yarn-site.xml. Primeiro, você precisa copiar o arquivo de mapred-site.xml.template para mapred-site.xml usando o seguinte comando.
$ cp mapred-site.xml.template mapred-site.xml
Abra o arquivo mapred-site.xml e adicione as seguintes propriedades entre as tags <configuration>, </ configuration> neste arquivo.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
————————————————————————–
Verificando a instalação do Hadoop.
As seguintes etapas são usadas para verificar a instalação do Hadoop.
Configure o namenode usando o comando “hdfs namenode -format” da seguinte maneira.
$ cd ~ $ hdfs namenode -format
O resultado esperado é o seguinte.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Verificando o Hadoop dfs
O comando a seguir é usado para iniciar dfs. Executando este comando irá iniciar o sistema de arquivos Hadoop.
$ start-dfs.sh
A saída esperada é a seguinte:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Verificando o script do yarn
O comando a seguir é usado para iniciar o script de yarn.
$ start-yarn.sh
A saída esperada é a seguinte:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Acessando o Hadoop no navegador
O número de porta padrão para acessar o Hadoop é 50070. Use o seguinte URL para obter os serviços do Hadoop no seu navegador.
http://localhost:50070/
A imagem a seguir mostra um navegador Hadoop.
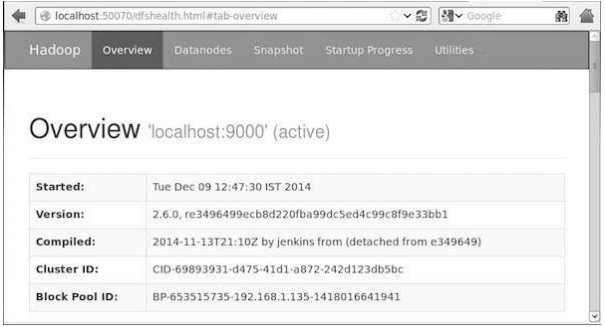
Verificar todos os aplicativos para cluster
O número de porta padrão para acessar todos os aplicativos do cluster é 8088. Use o seguinte URL para visitar esse serviço.
http://localhost:8088/
A imagem a seguir mostra o navegador de cluster Hadoop.
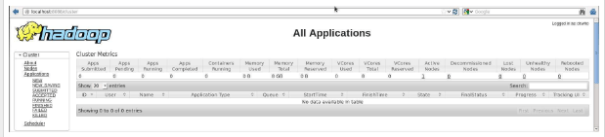


Deixe um comentário