
Este é um novo capítulo dentro do blog, falaremos um pouco, ou melhor, colocaremos a mão na massa com relação a programação.
A linguagem escolhida é Python. Mas, porque Python?
Python hoje está em ascensão devido a sua versatilidade em implementação, facilidade de aprendizado, facilidade com que se pode administrar servidores tanto Windows quanto Linux, criação de rotinas, padronização de processos com “robôs” e claro, sua grande interação com as novas tecnologias como Spark, Hadoop, pacotes de data science, inteligência artificial entre outros… No link você encontra 10 motivos para aprender Python 10 Motivos para aprender Python.
Não vou entrar em maiores detalhes, pois, nosso intuito é mão na massa. Quem tiver interesse em saber sobre instalação, realizei um post sobre onde pode ser acessado através do link Instale Python.
Vamos lá!!
Estudo de caso:
Administro alguns servidores de banco de dados onde nesses servidores possuo algumas dezenas de bases que tem habilitado o backup de log de transação. Para cada base de dados em cada servidor existe uma pasta que é guardado o backup de log de transação onde por dia são adicionados um total de 3000 arquivos .trn. Cada base possui sua pasta diretório e cada um deles é criado seu respectivo backup de log de transação.
Objetivo:
Automatizar a exclusão dos arquivos de log de transação (.trn) deixando apenas os arquivos do dia corrente. Poderia deixar mais dias? Sim! Mas, em nosso caso foi definido na regra de negócio da empresa não havendo necessidade de deixar mais tempo já que os arquivos são transferidos para um servidor de backup todas as noites.
Mas Hudson, porque usar python? porque sofrer? com uma bat eu faço em 10 minutos. Com um T-SQL faço em 5 minutos a rotina. Sim, sei bem, mas, se você vê uma necessidade e pode aprender em cima dela uma nova linguagem, porque não? Muito bom motivo para apanhar aprender. E na maioria das minhas melhores experiências que tive com banco de dados foi realmente apanhando MUITO.
Sem mais delongas, vamos ao código.
Obs: Não sou especialista python, então com certeza deve haver uma forma mais fácil de realizar a tarefa, mas, a que indico a baixo funciona que é uma beleza… rs..
Tecnologias utilizadas:
- Python 3.0;
- Sublime; (Facilita na indentação e fatoramento de condigo).
- Jupyter-notebook; (Excelente ferramenta para realizar testes e rodar os scripts).
- SQL Server; (Tabelas de referencias e log).
Criaremos duas pastas que será a pasta base e a de classes. Sim, vamos encapsular o código para tentar deixar mais limpo possível e facilitar qualquer eventual manutenção. Fique a vontade para modificar a sua maneira e claro, fazer sugestões, críticas etc…
Criei em meu ambiente a pasta Python /documents/Python e dentro dela a pasta Class /documents/Python/Class.
Iremos começar com a criação das tabelas base e log no SQL Server. (Fique a vontade para testar em outros bancos, mas, lembrando que a string de conexão do Python para o BD será diferente).
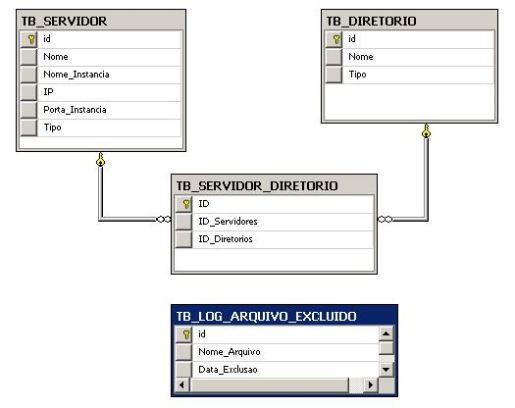
Script criação das tabelas:
CREATE TABLE [dbo].[TB_DIRETORIO]( [id] [int] IDENTITY(1,1) NOT NULL, [Nome] [varchar](1000) NULL, [Tipo] [varchar](50) NULL, CONSTRAINT [PK_Diretorios] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO CREATE TABLE [dbo].[TB_SERVIDOR]( [id] [int] IDENTITY(1,1) NOT NULL, [Nome] [varchar](50) NOT NULL, [Nome_Instancia] [varchar](50) NULL, [IP] [varchar](30) NOT NULL, [Porta_Instancia] [int] NOT NULL, [Tipo] [varchar](50) NOT NULL, CONSTRAINT [PK_TB_SERVIDORES] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO CREATE TABLE [dbo].[TB_SERVIDOR_DIRETORIO]( [ID] [int] IDENTITY(1,1) NOT NULL, [ID_Servidores] [int] NULL, [ID_Diretorios] [int] NULL, PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[TB_SERVIDOR_DIRETORIO] WITH CHECK ADD CONSTRAINT [FK_TB_SERVIDORES_DIRETORIOS_TB_DIRETORIOS] FOREIGN KEY([ID_Diretorios]) REFERENCES [dbo].[TB_DIRETORIO] ([id]) GO ALTER TABLE [dbo].[TB_SERVIDOR_DIRETORIO] CHECK CONSTRAINT [FK_TB_SERVIDORES_DIRETORIOS_TB_DIRETORIOS] GO ALTER TABLE [dbo].[TB_SERVIDOR_DIRETORIO] WITH CHECK ADD CONSTRAINT [FK_TB_SERVIDORES_DIRETORIOS_TB_SERVIDORES] FOREIGN KEY([ID_Servidores]) REFERENCES [dbo].[TB_SERVIDOR] ([id]) GO ALTER TABLE [dbo].[TB_SERVIDOR_DIRETORIO] CHECK CONSTRAINT [FK_TB_SERVIDORES_DIRETORIOS_TB_SERVIDORES] GO CREATE TABLE [dbo].[TB_LOG_ARQUIVO_EXCLUIDO]( [id] [int] IDENTITY(1,1) NOT NULL, [Nome_Arquivo] [varchar](500) NULL, [Data_Exclusao] [datetime] NULL, CONSTRAINT [PK_TB_LOG_ARQUIVO_EXCLUIDO] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[TB_LOG_ARQUIVO_EXCLUIDO] ADD CONSTRAINT [DF_TB_LOG_ARQUIVO_EXCLUIDO_Data_Exclusao] DEFAULT (getdate()) FOR [Data_Exclusao] GO
Vamos tomar de exemplo dois servidores:
- Servidor: Server01 / Instancia: InstanceBD01 / IP: 192.168.10.1 / Porta: 91433 / Tipo: <Produção/homologação/teste>
- Servidor: Server02 / Instancia: InstanceBD02 / IP: 192.168.10.2 / Porta: 91433 / Tipo: <Produção/homologação/teste>
Inserindo algumas linhas nas tabelas:
INSERT INTO [dbo].[TB_SERVIDOR]
([Nome],[Nome_Instancia],[IP],[Porta_Instancia],[Tipo])
VALUES('Server01', 'InstanceBD01', '192.168.10.1', 91433, 'Teste')
GO
INSERT INTO [dbo].[TB_SERVIDOR]
([Nome],[Nome_Instancia],[IP],[Porta_Instancia],[Tipo])
VALUES('Server02', 'InstanceBD02', '192.168.10.2', 91433, 'Teste')
GO
INSERT INTO [dbo].[TB_DIRETORIO]
([Nome],[Tipo])
VALUES ('\X$\CL01-INST01-BKP-LOG' ,'T-LOG')
GO
INSERT INTO [dbo].[TB_DIRETORIO]
([Nome],[Tipo])
VALUES ('\Y$\CL01-INST01-BKP-LOG' ,'T-LOG')
GO
Vamos relacionar as informações:
Diretório X do Server01 e diretório Y do Servidor02
INSERT INTO [dbo].TB_SERVIDOR_DIRETORIO (ID_Servidores, ID_Diretorios) VALUES ( 1, 1 ) GO INSERT INTO [dbo].TB_SERVIDOR_DIRETORIO (ID_Servidores, ID_Diretorios) VALUES ( 2, 2 ) GO
A tabela de log será preenchida automaticamente pela rotina.
Após definido os servidores e seus respectivos diretórios vamos começar definido as classes do Python:
Conexão banco de dados
Criaremos a conexão de banco de dados para que seja buscado as informações das tabelas base e efetuar a inserção do log. Como é uma classe genérica, pode ser reutilizada em outro códigos como veremos em adiante:
class Conn_BancoDeDados:
def connect():
import pyodbc
server = 'tcp:192.168.20.1,91433'
database = 'DB_GERENCIA'
username = 'app_python'
password = '123@345'
cnxn = pyodbc.connect('DRIVER={ODBC Driver 13 for SQL Server};SERVER='+server
+';DATABASE='+database+';UID='+username+';PWD='+ password)
return cnxn
Classe seleciona_diretorio
A classe seleciona_diretorio chamamos a classe de conexão com o banco de dados, importamos o pandas (usaremos ao longo das classes) e passamos a query com a busca dos dados de servidores e diretórios dando como saída um dataframe:
class seleciona_diretorio: def servidor_diretorio(): from Class.CONNECT import Conn_BancoDeDados import pandas as pd conn = Conn_BancoDeDados.connect() query = """SELECT S.IP, D.NOME AS DIRETORIO FROM TB_SERVIDOR AS S INNER JOIN TB_SERVIDOR_DIRETORIO SD ON S.ID=SD.ID_SERVIDORES INNER JOIN TB_DIRETORIO D ON D.ID=SD.ID_DIRETORIOS WHERE S.TIPO = 'PRODUCAO'""" src_read = pd.read_sql(query, conn) return src_read
Ficamos atento com a classe a cima, pois, sua saída será tratada no código base que é a rotina que chama todas as classes alem de fazer o tratamento do dataframe.
Por agora vou explicar cada classe que será chamada no código base.
Classe quebra_extensao
Ela tem como parâmetro de entrada o nosso dataframe que nada mais é do que o caminho inteiro do diretório onde é armazenado os logs, busca cada um dos arquivos que está dentro do diretório, separa o nome do arquivo da extensão do mesmo e passa a extensão do arquivo, nome do arquivo e o caminho completo para a próxima classe tratar essa informação:
class quebra_extensao:
def quebra(item):
import os
import pandas as pd
for p, _, files in os.walk(os.path.abspath(item)):
# QUEBRA EXTENSÃO DO ARQUIVO
for file in files:
path = os.path.join(p, file)
# Explode o arquivo em cada ponto (.)
explod_file = file.split('.')
# Apenas o nome do arquivo
only_name = '.'.join(explod_file[:-1])
# Extensão do arquivo
extension = explod_file[-1]
extension = pd.Series(extension)
busca_extensao.busca_trn(extension, path, file)
Classe busca_extensao
Basicamente está classe verifica se o arquivo é um arquivo .trn (arquivo de log de transação), retorna o cabeçalho do arquivo, busca a data do cabeçalho e formata para ser comparada com a data atual. Caso a data do cabeçalho do arquivo seja diferente da data atual, chama a classe deleta_arquivo.
class busca_extensao:
def busca_trn(extension, path, file):
import time, datetime, os
for extensao in extension:
if(extensao == 'TRN'):
# Busca informações da data no cabeçalho do diretório/arquivo
path = path
stats = os.stat(path)
lastmod_date = time.localtime(stats[8])
date_file_tuple = lastmod_date, file
# "retira" a data do cabeçalho e realiza sua formatação
folder, file_name = os.path.split(date_file_tuple[1])
file_date = time.strftime("%m/%d/%Y", date_file_tuple[0])
# Data atual
date_now = datetime.date.today()
date_now_year = time.strftime('%m/%d/%Y')
# Deleta o arquivo caso seja diferente da data atual
deleta_arquivo.delete(path, date_now_year, file_date)
else:
print(format(path) + ": ARQUIVO NÃO EXCLUIDO. EXTENSÃO DIFERENTE DE .TRN : ")
Classe deleta_arquivo
A classe deleta_arquivo faz a comparação entre as datas do cabeçalho com a data atual de sistema, remove os arquivos que não são do dia corrente e insere na tabela TB_LOG_ARQUIVO_EXCLUIDO o caminho com o nome do arquivo completo:
class deleta_arquivo:
def delete(path, date_now_year, file_date):
from Class.CONNECT import Conn_BancoDeDados
import pandas as pd
import pyodbc, os
# Copara as datas de arquivo com data atual
if (date_now_year != file_date):
df_path = {'Diretorio_Arquivo' : [path]}
df=pd.DataFrame(df_path)
# Abre conexão com banco de dados
conn = Conn_BancoDeDados.connect()
# Remove arquivos .TRN
os.remove(path)
query = ("INSERT INTO TB_LOG_ARQUIVO_EXCLUIDO (Nome_Arquivo) VALUES (?)")
VALUES = [path] #path #[Id,firstname,LastName,RegisterNo]
cursor = conn.cursor()
cursor.execute(query, VALUES)
conn.commit()
conn.close()
else:
print('ARQUIVO NÃO EXCLUIDO. DATA ATUAL: ' + path, file_date)
CODIGO BASE
Basicamente usaremos três códigos no tratamento:
Adiciona uma coluna concatenando servidor e diretório. Também adicionamos uma barra a mais a frente do nome do servidor para que seja efetuado a busca como fazemos no Windows, exemplo: \\192.168.160.1\c$.
src_read = src_read["IPDIRETORIO"] = '\\\\'+ src_read.iloc[:,0] + src_read["DIRETORIO"]

Podemos analisar a cima que nosso dataframe está com três colunas e fizemos uma conferencia para validar se nossa variável realmente é um dataframe.
Bom, já realizamos o ETL do diretório adicionando a nova coluna com a formatação que precisávamos, podemos agora excluir as outras colunas do dataframe. A memória do seu pc agradece.
src_read = src_read.drop(['IP', "DIRETORIO"], axis=1)
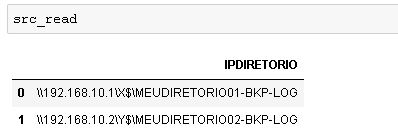
Que tal adicionar o dataframe a uma variável? Isso ajuda caso cometa algum erro no meio do caminho, não precisa importar tudo novamente, você pode voltar ao ponto do src_read.
directorys = src_read['IPDIRETORIO']
UFA… Não acabou ainda, vamos juntar tudo para que possamos excluir os arquivos:
from Class.EXTENSION_AND_DROP_FILES import seleciona_diretorio
from Class.EXTENSION_AND_DROP_FILES import quebra_extensao
from Class.EXTENSION_AND_DROP_FILES import busca_extensao
src_read = seleciona_diretorio.servidor_diretorio()
src_read["IPDIRETORIO"] = '\\\\'+ src_read.iloc[:,0] + src_read["DIRETORIO"]
directorys = src_read['IPDIRETORIO']
def Find_files(*args):
# Lista todos os arquivos em todos os diretórios
for item in args:
quebra_extensao.quebra(item)
E por fim, aplicaremos a classe ao dataframe:
src_read['IPDIRETORIO'].apply(Find_files)
Agora é só conferir na tabela de log:
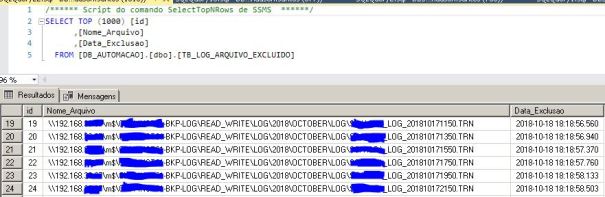
Por hoje é isso.
Temos um “robô” versátil, eficaz e escalavel podendo facilmente mudar as classes para outras tarefas com poucas alterações.
Existem maneiras mais fáceis? Obviamente. Mas, qual seria a graça?
;D



Parabens!👏👏👏
CurtirCurtir