
O CASSANDRA
Cassandra é um banco de dados distribuído, tolerante a falhas, peer-to-peer, sem um mestre, escalonável linearmente e descentralizado. Projetado para lidar com grandes volumes de dados, proporcionando tolerância a falhas e alta disponibilidade, sem uma única indicação de falha.
CASSANDAR CLUSTER
Todos os Nós no cluster tem o mesmo nome de cluster. Recomenda-se que todos os Nós tenham a mesma lista de Nós na configuração de seed. De preferência dois Nós inscritos no seed de cada datacenter.
Os Nós no seed são usados durante a inicialização e bootstrapping para descobrir outros Nós no cluster. Essas configurações podem ser encontradas em:
Cluster_name: <nome do cluster>
Seeds: <Endereço de IP dos Nós>
RAC
Rac é um conjunto lógico de Nós.
DATACENTER
Datacenter é um conjunto lógico de racs e Nós.
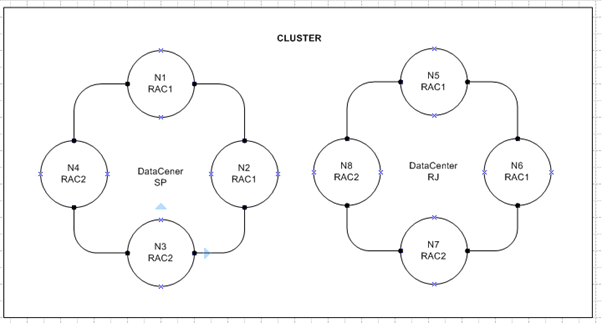
Como podemos ver no desenho acima, N1 e N2 fazem parte do Rac1 no DataCenter SP enquanto o N3 e N4 fazem parte do Rac2 também no DataCenter SP. Assim como N5 e N6 estão configurados no Rac1 do DataCenter RJ e os Nós N7 e N8 estão configurados no Rac2 do DataCenter RJ.
ARQUITETURA PEER-TO-PEER MASTER-LESS
Não existe conceito Master e Slave no Cassandra.
Cassandra lida com grandes cargas de trabalho em vários Nós, sem nenhum ponto de falha. Desenvolvido para ser altamente disponível e facilmente escalonável.
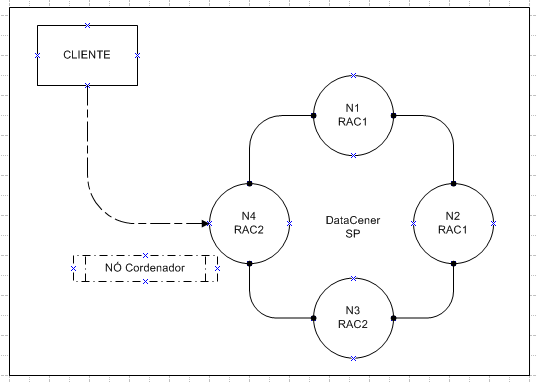
Os clientes podem se conectar a qualquer Nó para ler e escrever dados. O Nó ao qual o cliente está conectado é chamado de Nó coordenador.
GOSSIP PROTOCOL
Protocolo Gossip é o protocolo de comunicação dentro do cluster para suporte a descentralização e tolerância de partição.
Através do status de cada um dos Nós, eles descobrem informações sobre outros Nós e sobre a si mesmos. Gossip percorre a cada segundo em cada Nó. Ele consegue trocar informações de status com até três Nós aleatórios no cluster. Como um pulso ele vai verificando a localização, estado e data/hora do Nó.
Objetivo principal do Gossip é a detecção de falhas.
PRÁTICA RECOMENDADA:
Usar a mesma lista de Nós seed para todos os Nós para evitar qualquer problema de gossiping.
Em vários clusters de datacenter, inclua pelo menos dois Nós de cada datacenter na lista seed.
Se incluir apenas um Nó, o seed terá que se comunicar com outro datacenter se tiver que inicializar esse seed Nó. Quando se inclui mais de 1 Nó na lista seed o desempenho do Gossip fica o ideal. Não inclua todos os nós na lista de seed, pois isso reduzirá o desempenho do Gossip.
Os nós que são configurados na lista seed precisam iniciar primeiro. Conforme outros nós se juntam ao cluster, eles recebem informações do gossip seed e aprendem rapidamente sobre todos os outros Nós do cluster.
Chamamos de BOOTSTRAPPING a adição de outro Nó para uma expansão do cluster.
PARTIÇÃO DE DADOS
Os dados são gravados de forma transparentes e salvos em todos os nós do cluster. Cada Nó é responsável por essa parte do dado.
O particionamento mais comum utilizado é o Murmur3Partitioner. Isso pode ser configurado no arquivo cassandra.yaml.
#partitioners and tokens selection.
Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
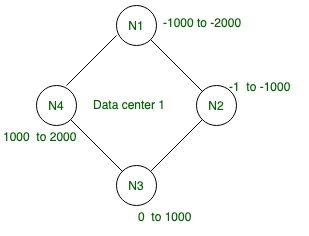
Uma vez o cluster inicializado com um particionador específico, ele não pode ser alterado. Cassandra particiona os dados num conjunto de Nós no cluster. Ele particiona os dados em todos os nós no intervalo possível de valores de hash de -2^63 até +2^63-1. Esses valores são chamados de valores de token. Quando uma linha é inserida em “uma tabela”, o Cassandra aplica a função hash à chave de partição e cria um valor de token consistente. Com base no valor do token para a chave de partição, a linha é inserida no Nó apropriado que possui esse intervalo de token.
Podemos encontrar Cassandra token calculator no site de referência https://www.geroba.com/cassandra/cassandra-token-calculator/.
HARDWARE
Cassandra o mínimo recomendado é 8GB memória e 32 GB em produção. Isso porque quanto mais dados ele armazena em cache, menor a chance que as buscas sejam necessárias em disco.
Também quantos mais núcleos melhor para o Cassandra. Cassandra trabalha altamente com concorrência e aproveitará vários núcleos. O mínimo recomendado são 4 cors para produção.
Armazenamento também é um ponto muito importante. O armazenamento compartilhado com o tipo de armazenamento compartilhado de capacidade pode ter um efeito significativamente negativo para o Cassandra.
Para entendermos, fisicamente se a cabeça do disco estiver sendo puxada para atender outros, levará mais tempo para atender o banco de dados.
O mais recomendado são os drivers de estado sólido SSD.
Geralmente, para desempenho é melhor ter mais nós em cluster com menos dados nele do que apenas alguns nós no cluster com muitos dados.
Quantidade recomendada de dados por nó varia com tipo de disco que está sendo usado, mas geralmente é de 500 GB a um terabyte para fornecer máximo desempenho de gravação.
Recomendável ter uma unidade separada para o log de confirmação. Este dispositivo para o commit pode ser bom um dispositivo diretório.
REPLICAÇÃO
Replicação de dados no cassandra é extremamente fácil configurar e manter. Ao contrário dos RDBMS tradicionais que não foram pensados na escablidadade horizontal, replicação nesses gerenciadores de banco de dados requerem uma configuração e manutenção que envolve complexidade e sem garantia de restauração em muitos dos casos.
No Cassandra cluster todos os Nós são envolvidos na replicação e agrupados logicamente, fisicamente ou Geo-distribuidos por datacenters. Não há necessidade de um software adicional para executar a replicação.
SIM, VOCÊ PODE REDUZIR A COMPLEXIDADE DE SEU AMBIENTE COM UMA BASE CASSANDRA.
Cassandra por ser um banco de dados distribuído, é totalmente voltado a tolerância a falhas. Você pode comparar as KeySpaces com Schemas em ORACLE ou tabelas do SQL Server/Mysql/PosgreSQL.
Veremos em postes mais a frente se Cassandra pode ser um substituto ou um agregador de ambiente. No final a decisão é do próprio leitor.
O fato aqui é, você não precisa de uma mão de obra extremamente especializada para realizar replicações de banco de dados, tabelas, schemas etc. De uma forma simples e objetiva Cassandra nos fornece uma replicação de dados totalmente voltado a performance e tolerância a falhas. Não citarei os cases de sucesso com este singelo SGDB, mas, focaremos em parte prática da coisa.
create keyspace first_space with replication={'class':'SimpleStrategy','replication_factor':3};E assim temos uma replicação com 3 copias.
- SIMPLESTRATEGY
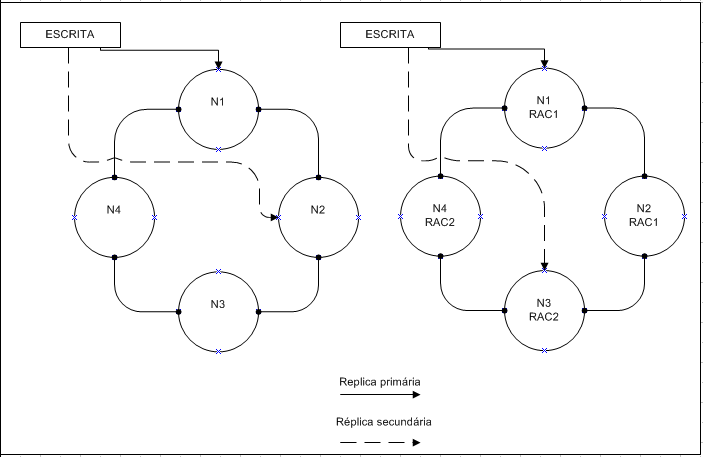
- Utilizado em um único datacenter e um único rac. Usado para ambientes de desenvolvimento. SimpleStrategy coloca a primeira réplica com base no nó determinado pelo particionador, réplicas adicionais são colocadas nos próximos nós no sentido horário no anel de acordo com o intervalo de tokens.
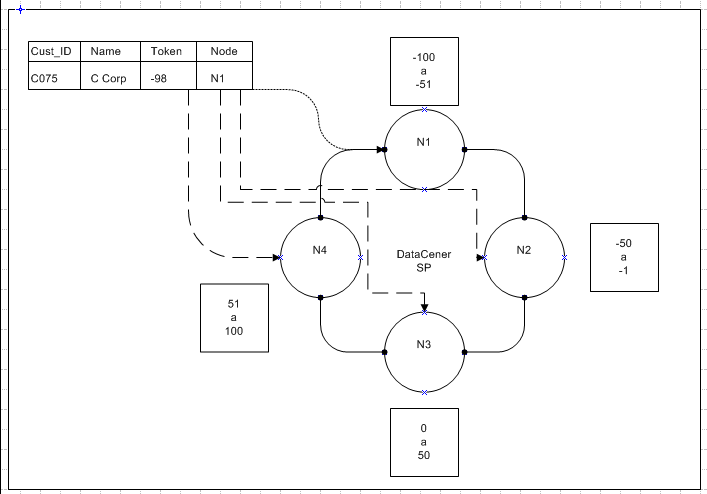
Na imagem a cima temos uma replicação de fator de três, ou seja, o dado será replicado para 3 nós no cluster pelo fator do range de token o dado é distribuído ao cluster para o Nó adjacente ao token correspondente. Neste caso o dado tem valor de -98 e o Nó N1 tem a distribuição de range de token entre -100 e -51. -98 entra dentro deste intervalo de range.
- NETWORKTOPOLOGYSTRATEGY
- Utilizado quando temos configurado multiplos datacenters. Podemos especificar o fator de replicação para cada datacenter. O cassandra usa informantes para descobrir a topologia geral da rede, que é configurada no arquivo cassandra-rack dc.properties. Quando gravamos dados, essa estratégia coloca réplicas em cada datacenter. Ele coloca a primeira réplica com base no nó determinado pelo particionador e as réplicas subsequentes no anel no sentido horário até atingir o primeiro nó com uma configuração de rack diferente. ao configurar a política de rede, deve-se prestar muita atenção para configurá-la adequadamente. por exemplo, cada rack deve ter o mesmo número de nós no datacenter. Caso contrário, o uso de disco de alguns nós será maior e isso criará pontos de acesso no cluster.
- Workload separation (Separação por carga de trabalho).
- Replicações para diferentes datacenters. Assim podemos separar carga de trabalho da carga de trabalho de relatórios.
{'dc_transaction':3, 'dc_report',3}
- Localização geográfica.
- Podemos ter diferentes datacenters separados geograficamente. Ambos os datacenters podem fazer parte do mesmo cluster. Exemplo: Um datacenter no Brasil e outro na Europa e ambos serem parte de um mesmo cluster Cassandra.
{'dc_Brasil':3, 'dc_EUROPE':3}
- Backup.
- Podemos dedicar um datacenter somente para backups online. Exemplo:
{'dc_Brasil':3, 'dc_EUROPA':3, 'dc_report':3, 'dc_backup':2}
CONSISTENCIA
cassandra é um banco de dados distribuído linearmente escalável e altamente disponível. É um (disponibilidade/telerância partição) sistema de acordo com o teorema cap. Consistência significa que todos os usuários veem os mesmos dados, mesmo quando o sistema está passando por atualizações simultâneas. Em um sistema distribuído como cassandara, para torná-lo disponível e tolerante a partição, os dados são geralmente replicados para nós de vários arquivos e datacenters. Quando atualizamos os dados, pode levar algum tempo para chegar a todos os nós onde deveriam ser replicados. Isso cria a possibilidade de um usuário ler os dados de um nó onde a gravação ainda não foi alcançada e os dados são inconsistentes. esses dados eventualmente se tornarão consistentes.
Podemos ler mais sobre o nível de consistência do Cassandra e suas implicações:
| Nível consistência | Implicações |
| ANY | Aplicável somente para operações de gravação. Garante que a escrita seja bem sucedida em um nó ou pelo coordenador escrever hints. Se o hint for armazenado, o coordenador tomará mais tarde para entregar as escritas a todas as réplicas. Não sugerido para produção. |
| ONE | Um nó precisa responder para read/write. |
| LOCAL_ONE | Um nó precisa responder para read/write. Em um multi datacenter, o read/write não será enviado para réplicas do data center remoto. |
| TWO | Dois nós precisam responder para read/write. |
| THREE | Três nós precisam responder para read/write. |
| QUORUM | Maioria dos nós precisam responder. (Fator de replicação/2) +1 para um determinado keyspace, se replication_factor = 3, significa para QUORUM, 2 nós precisam responder. Para replication_factor = 7, 4 nós precisam responder. A resposta pode ser de todos os datacenters envolvidos. |
| LOCAL_QUORUM | Semelhante ao QUORUM, mas, somente para datacenter local. |
| EACH_QUORUM | Necessita da resposta da maioria dos nós de todos os datacenters do cluster. |
| ALL | Toda a replica deve responder isso inclúi todos os datacenters. Reduz bem a disponibilidade. Os hints escritos pelo coordenador não são considerados como sucesso para a consistência de ALL. |
Podemos alterar a consistência mudando através das queries. O nível de resposta da consistência é baseado no fator de replicação no keyspace e não no número total de nós no datacenter ou cluster.
Considere utilizar o nível de consistência ONE ou ALL somente em ambiente de desenvolvimento ou QA.
Como exemplo se tivermos N1, N2, N3 E N4 em um cluster e fator de replicação = 3 e consistência nível QUORUM. Suponhamos que o dado seja escrito no nó N1 e N2, mas, em N3 falhe. Neste caso a escrita foi com sucesso em dois nós de três satisfazendo a consistência QUORUM. Dado que a escrita no N3 falhou, temos uma inconsistência deste nó ao restante do cluster. Se um SELECT query com consistência de nível ONE e o coordenador envia o SELECT para o N3, serão retornados dados desatualizados do restante do cluster.
Nos próximos capítulos falaremos de Keyspaces, tokens e vnodes….
abs.


Deixe um comentário