
Estamos vendo uma crescente demanda para com a área hoje considerada “charme da TI”. Atualmente é impossível ignorar a importância contínua e a de analisá-los e contextualizá-los.
O site Glassdor classificou como a carreira de cientista de dados em PRIMEIRO lugar entre os 50 melhores e mais bem pagos cargos das Américas: Glassdoor – 50 melhores cargos. Então, é papel relativamente “novo” e com cada vez mais importância na sociedade e nas companhias.
Embora saber programar bem seja importante, ciência de dados não é toda ou tão somente engenharia de software, na verdade um pouco de familiaridade com Python já é o suficiente para emergir. Cientista de dados vive na inserção de codificação, estatística e pensamento crítico.
Do que adianta saber TensorFlow, criar uma estrutura inteira de hadoop/apache Spark e não saber como ou onde irá aplicar? O que quero dizer é que uma estrutura teórica para aprendizado de máquina começa a partir dos campos da estatística e análise funcional onde darão base para mineração de dados.
Segue alguns exemplos das aplicações “projetos” onde machine learning pode ser aplicado:
- Prever se alguém terá um ataque cardíaco com base em medidas demográficas, diéticas e clima.
- Analisar qual o provável horário que uma pessoa estará acordada com base em histórico de horários que uma pessoa está indo para cama, sua quantidade de horas de sono por dia etc. (Eficiente para call centers não serem inconvenientes e ligar fora de horário).
- Identifique os números em um CEP manuscrito.
- Personalize um sistema detecção de spam por email.
- Estabelecer a relação entre as varáveis salariais e demográficas nos dados de pesquisa populacional.
- Analisar o peso médio por eixo de um caminhão que passa por uma balança de pesagem.
 Estudo Machine Learning já a pouco mais de 3 anos e hoje com um olhar mais crítico e uma base como cursos de MBA Data Science (IGTI – Instituto Gestão e Tecnologia), formação em cientista de dados DataScienceAcademy e alguns livros como os que minha gata está correndo independente e alguns online como o excelente An Introduction to Statistical Learning, além de fóruns, sites, blogs que tenho acompanhado com frequência (ainda farei um post com uma lista desses últimos), venho compartilhar com vocês 10 técnicas para nenhum cientista de dados botar defeito.
Estudo Machine Learning já a pouco mais de 3 anos e hoje com um olhar mais crítico e uma base como cursos de MBA Data Science (IGTI – Instituto Gestão e Tecnologia), formação em cientista de dados DataScienceAcademy e alguns livros como os que minha gata está correndo independente e alguns online como o excelente An Introduction to Statistical Learning, além de fóruns, sites, blogs que tenho acompanhado com frequência (ainda farei um post com uma lista desses últimos), venho compartilhar com vocês 10 técnicas para nenhum cientista de dados botar defeito.
O título deveria ser 10 técnicas indispensáveis para cientista de dados, mas, achei interessante dar uma expressão alá Brasileira.
Uma nota sobre Big Data
Paradoxalmente, os problemas analíticos preditivos do big data são realmente resolvidos por algoritmos relativamente simples [2] [4]. Assim, podemos argumentar que a dificuldade de predição do big data não está no algoritmo usado, mas sim nas dificuldades computacionais de armazenamento e execução em big data. (Deve-se também considerar a citação de Gelman acima e perguntar "Eu realmente tenho big data?")
Os problemas analíticos, muito mais difíceis, envolvem dados médios e, especialmente, dados realmente problemáticos. Usando um argumento similar ao de Gelman acima, se os problemas de big data são grandes o suficiente para serem prontamente resolvidos, então deveríamos estar mais interessados nos conjuntos de dados não suficientemente grandes.
1 – Regressão Linear:
Na estatística, a regressão linear é um método para prever uma variável-alvo ajustando a melhor relação linear entre a variável dependente e a independente. O melhor ajuste é feito certificando-se de que a soma de todas as distâncias entre a forma e as observações reais em cada ponto seja a menor possível. O ajuste da forma é “melhor” no sentido de que nenhuma outra posição produziria menos erros, dada a escolha da forma.
2 tipos principais de regressão linear são Regressão Linear Simples e Regressão Linear Múltipla .
- A Regressão Linear Simples usa uma única variável independente para prever uma variável dependente, ajustando uma melhor relação linear.
- A Regressão Linear Múltipla usa mais de uma variável independente para prever uma variável dependente, ajustando um melhor relacionamento linear.

Pense em duas coisas em sua vida que se relacionam: Vamos como exemplo gasto mensal de gasolina, renda mensal e número de viagens por mês nos últimos 3 anos. Regressão linear pode ajudar a responder:
Qual será meu gasto mensal para o próximo ano?
Quais cidades poderão estar enquadradas dentro da distância que poderei percorrer sem comprometer minha renda mensal para próximo ano?
Como renda mensal e viagens por mês estão correlacionadas com os gastos mensais?
2 – Classificação:
A classificação é uma técnica de mineração de dados que atribui categorias a uma coleção de dados para auxiliar em previsões e análises mais precisas. Também às vezes chamada de Árvore de Decisão, a classificação é um dos vários métodos para tornar efetiva a análise de conjuntos de dados muito grandes. 2 principais técnicas de classificação se destacam: Regressão Logística e Análise Discriminante .
Regressão Logística é a análise de regressão apropriada para conduzir quando a variável dependente é dicotômica (binária). Como todas as análises de regressão, a regressão logística é uma análise preditiva. A regressão logística é usada para descrever dados e para explicar a relação entre uma variável binária dependente e uma ou mais variáveis independentes nominais, ordinais, de intervalo ou de nível de razão. Tipos de perguntas que uma regressão logística pode examinar:
- Como a probabilidade de contrair câncer de pulmão (Sim vs Não) varia para cada quilo adicional de sobrepeso e para cada maço de cigarros fumados por dia?
- A ingestão calórica, o consumo de gordura e a idade dos participantes têm influência nos ataques cardíacos (Sim vs Não)?
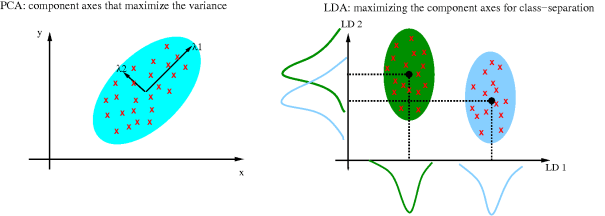
Na Análise Discriminante , 2 ou mais grupos ou grupos ou populações são conhecidos a priori e 1 ou mais novas observações são classificadas em 1 das populações conhecidas com base nas características medidas. A análise discriminante modela a distribuição dos preditores X separadamente em cada uma das classes de resposta, e então usa o teorema de Bayes para transformá-los em estimativas para a probabilidade da categoria de resposta dada o valor de X. Tais modelos podem ser lineares ou quadráticos. .
- A Análise Discriminante Linear calcula os “escores discriminantes” para cada observação para classificar em que classe de variável de resposta está. Esses escores são obtidos pela localização de combinações lineares das variáveis independentes. Assume-se que as observações dentro de cada classe são extraídas de uma distribuição Gaussiana multivariada e a covariância das variáveis preditoras é comum em todos os k níveis da variável de resposta Y.
- Análise Discriminante Quadrática fornece uma abordagem alternativa. Assim como o LDA, o QDA assume que as observações de cada classe de Y são extraídas de uma distribuição gaussiana. No entanto, ao contrário do LDA, o QDA assume que cada classe tem sua própria matriz de covariância. Em outras palavras, as variáveis preditoras não são consideradas como tendo variância comum em cada um dos níveis k em Y.
3 – Métodos de Reamostragem:
Reamostragem é o método que consiste em desenhar amostras repetidas das amostras de dados originais. É um método não paramétrico de inferência estatística. Em outras palavras, o método de reamostragem não envolve a utilização de tabelas genéricas de distribuição para calcular valores aproximados de probabilidade p.
A reamostragem gera uma distribuição de amostragem única com base nos dados reais. Utiliza métodos experimentais, em vez de métodos analíticos, para gerar a distribuição única de amostragem. Ele produz estimativas imparciais, pois é baseado nas amostras imparciais de todos os resultados possíveis dos dados estudados pelo pesquisador. Para entender o conceito de resampling, você deve entender os termos Bootstrapping e Cross-Validation :
- Bootstrapping é uma técnica que ajuda em muitas situações, como a validação de um desempenho de modelo preditivo, métodos de conjunto, estimativa de viés e variância do modelo. Ele funciona por amostragem com substituição dos dados originais e toma os pontos de dados ” não escolhidos ” como casos de teste. Podemos fazer isso várias vezes e calcular a pontuação média como estimativa do desempenho do nosso modelo.
- Por outro lado, a validação cruzada é uma técnica para validar o desempenho do modelo, e é feita dividindo os dados de treinamento em k partes. Nós tomamos as partes k – 1 como nosso conjunto de treinamento e usamos a parte ” retida ” como nosso conjunto de teste. Repetimos isso k vezes de forma diferente. Finalmente, tomamos a média das pontuações k como nossa estimativa de desempenho.
Geralmente, para modelos lineares, os mínimos quadrados ordinários são os principais critérios a serem considerados para ajustá-los aos dados.
Os próximos 3 métodos são as abordagens alternativas que podem fornecer melhor precisão de previsão e interpretação do modelo para ajustar modelos lineares e serão discutidos no próximo post.
Até lá!


[…] Dando continuidade a série 10 técnicas para nenhum cientista de dados botar defeito está é a série 2 / 3. Quem não viu a primeira fica o link de acesso: Primeira parte. […]
CurtirCurtir