
Dando continuidade a série 10 técnicas para nenhum cientista de dados botar defeito está é a série 2 / 3. Quem não viu a primeira fica o link de acesso: Primeira parte.
4 – Seleção de subconjuntos:
Essa abordagem identifica um subconjunto dos preditores p que acreditamos estar relacionados à resposta. Em seguida, ajustamos um modelo usando os mínimos quadrados dos recursos do subconjunto.
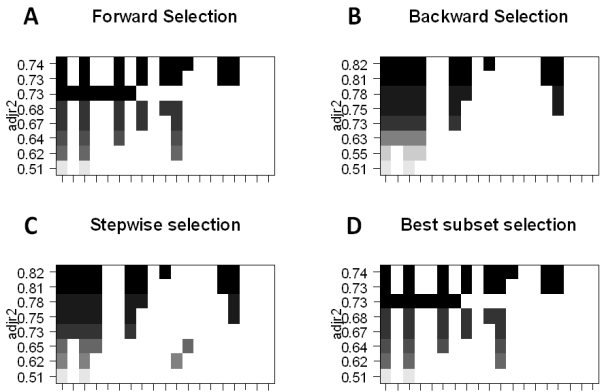
- Seleção de Melhor Subconjunto: Aqui nós ajustamos uma regressão OLS separada para cada combinação possível dos preditores p e então olhamos para os ajustes de modelo resultantes. O algoritmo é dividido em dois estágios: (1) Ajusta todos os modelos que contêm k preditores, onde k é o comprimento máximo dos modelos, (2) seleciona um modelo único usando um erro de previsão validado de forma cruzada. É importante usar erro de teste ou validação, e não erro de treinamento para avaliar o ajuste do modelo, pois o RSS e o R² aumentam monotonicamente com mais variáveis. A melhor abordagem é a validação cruzada e escolha do modelo com o maior R² e menor RSS em estimativas de erro de teste.
- Forward Stepwise Selection considera um subconjunto muito menor de preditores p . Ele começa com um modelo que não contém nenhum preditor e, em seguida, adiciona os preditores ao modelo, um de cada vez, até que todos os preditores estejam no modelo. A ordem das variáveis que estão sendo adicionadas é a variável, que fornece a maior melhoria adicional ao ajuste, até que nenhuma outra variável melhore o ajuste do modelo usando erros de previsão validados de forma cruzada.
- A seleção progressiva por etapas começa com todos os preditores p no modelo e, em seguida, remove iterativamente o preditor menos útil, um de cada vez.
- Métodos híbridos segue a abordagem forward stepwise, no entanto, após adicionar cada nova variável, o método também pode remover variáveis que não contribuem para o ajuste do modelo.
5 – Encolhimento:
Esta abordagem se encaixa em um modelo envolvendo todos os preditores p , no entanto, os coeficientes estimados são encolhidos para zero em relação às estimativas de mínimos quadrados. Este encolhimento, também conhecido como regularização, tem o efeito de reduzir a variação. Dependendo do tipo de encolhimento, alguns dos coeficientes podem ser estimados como exatamente zero. Assim, este método também realiza seleção de variáveis. As duas técnicas mais conhecidas para reduzir as estimativas dos coeficientes em direção ao zero são a regressão da crista e o laço .
- A regressão de Ridge é semelhante aos mínimos quadrados, exceto que os coeficientes são estimados minimizando uma quantidade ligeiramente diferente. A regressão de Ridge, assim como o OLS, busca estimativas de coeficientes que reduzem o RSS, mas também têm uma penalidade de encolhimento quando os coeficientes se aproximam de zero. Essa penalidade tem o efeito de reduzir as estimativas dos coeficientes para zero. Sem entrar na matemática, é útil saber que a regressão de rebordo reduz os recursos com a menor variação de espaço da coluna. Como na análise de componente principal, a regressão de crista projeta os dados no espaço direcional e então reduz os coeficientes dos componentes de baixa variância mais do que os componentes de alta variância, que são equivalentes aos maiores e menores componentes principais.
- A regressão de Ridge teve pelo menos uma desvantagem; inclui todos os preditores p no modelo final. O termo de penalidade definirá muitos deles próximos de zero, mas nunca exatamente a zero. Isso geralmente não é um problema para precisão de previsão, mas pode tornar o modelo mais difícil de interpretar os resultados. Lasso supera essa desvantagem e é capaz de forçar alguns dos coeficientes a zero, desde que seja pequeno o suficiente. Como s = 1 resulta em regressão OLS regular, à medida que s se aproxima 0, os coeficientes encolhem para zero. Assim, a regressão de Lasso também executa a seleção de variáveis.
6 – Redução de Dimensão:
A redução de dimensão reduz o problema de estimar os coeficientes p + 1 para o problema simples dos coeficientes M + 1 , onde M <p. Isso é obtido pela computação de M combinações lineares diferentes, ou projeções, das variáveis. Então, essas projeções M são usadas como preditores para ajustar um modelo de regressão linear por mínimos quadrados. 2 abordagens para esta tarefa são regressão de componentes principais e mínimos quadrados parciais:
 Pode-se descrever a Regressão de Componentes Principais como uma abordagem para derivar um conjunto de características de baixa dimensão a partir de um grande conjunto de variáveis. A primeira direção do componente principal dos dados é ao longo da qual as observações variam mais. Em outras palavras, o primeiro PC é uma linha que se ajusta o mais próximo possível dos dados. Pode-se ajustar a componentes principais distintos. O segundo PC é uma combinação linear das variáveis que não é correlacionada com o primeiro PC e tem a maior variação sujeita a essa restrição. A ideia é que os componentes principais capturem a maior variação nos dados usando combinações lineares dos dados em direções ortogonais subsequentes. Dessa forma, também podemos combinar os efeitos das variáveis correlacionadas para obter mais informações dos dados disponíveis, enquanto nos mínimos quadrados regulares teríamos que descartar uma das variáveis correlacionadas.
Pode-se descrever a Regressão de Componentes Principais como uma abordagem para derivar um conjunto de características de baixa dimensão a partir de um grande conjunto de variáveis. A primeira direção do componente principal dos dados é ao longo da qual as observações variam mais. Em outras palavras, o primeiro PC é uma linha que se ajusta o mais próximo possível dos dados. Pode-se ajustar a componentes principais distintos. O segundo PC é uma combinação linear das variáveis que não é correlacionada com o primeiro PC e tem a maior variação sujeita a essa restrição. A ideia é que os componentes principais capturem a maior variação nos dados usando combinações lineares dos dados em direções ortogonais subsequentes. Dessa forma, também podemos combinar os efeitos das variáveis correlacionadas para obter mais informações dos dados disponíveis, enquanto nos mínimos quadrados regulares teríamos que descartar uma das variáveis correlacionadas.- O método de PCR que descrevemos acima envolve a identificação de combinações lineares de X que melhor representam os preditores. Essas combinações ( direções ) são identificadas de maneira não supervisionada, uma vez que a resposta Y não é usada para ajudar a determinar as direções do componente principal. Ou seja, a resposta Y não supervisiona a identificação dos componentes principais, portanto, não há garantia de que as direções que melhor explicam os preditores também sejam as melhores para prever a resposta (mesmo que isso seja frequentemente assumido).
- Os mínimos quadrados parciais (PLS) são uma alternativa supervisionada à PCR. Como o PCR, o PLS é um método de redução de dimensão, que primeiro identifica um novo conjunto menor de recursos que são combinações lineares dos recursos originais e, então, ajusta um modelo linear via mínimos quadrados aos novos recursos do M. No entanto, ao contrário da PCR, o PLS faz uso da variável de resposta para identificar os novos recursos.
Próximo post falaremos de modelos lineares, Bayesianos e muito mais.


Deixe um comentário